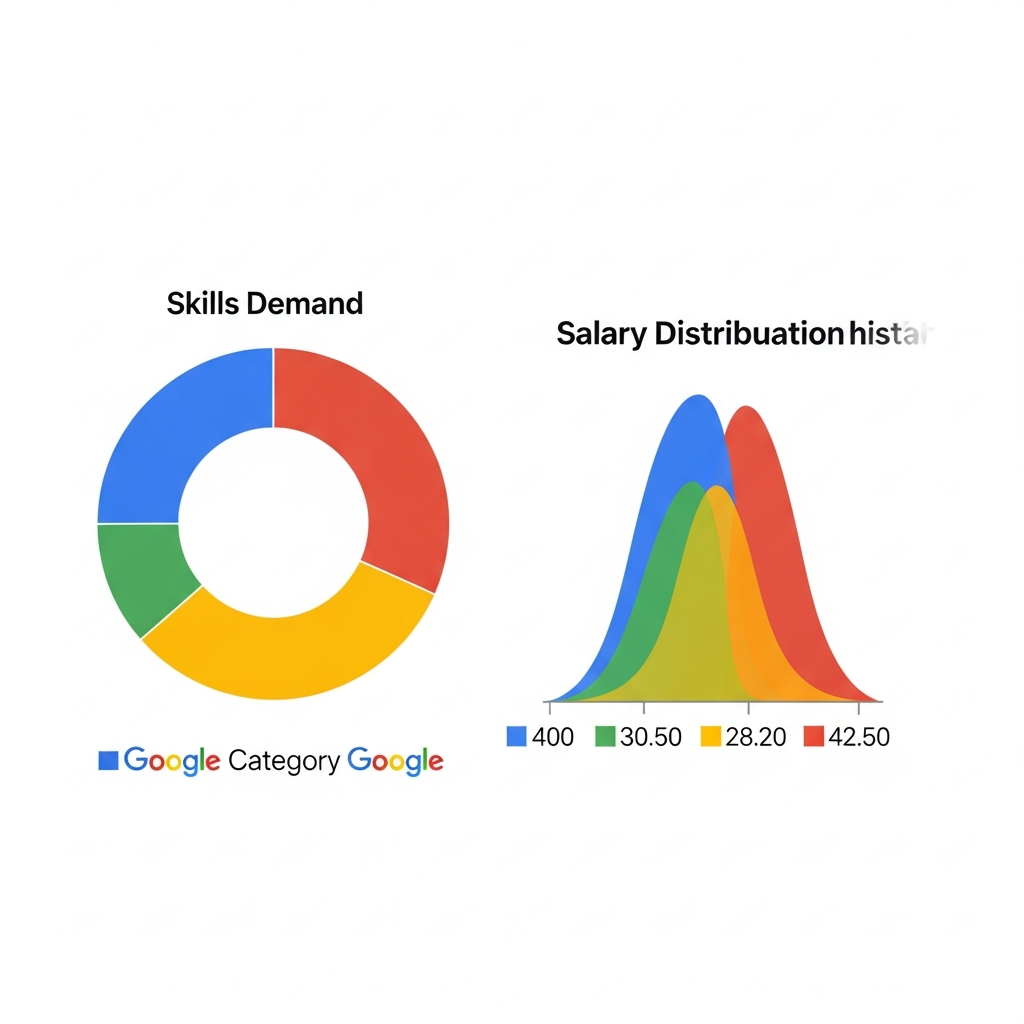
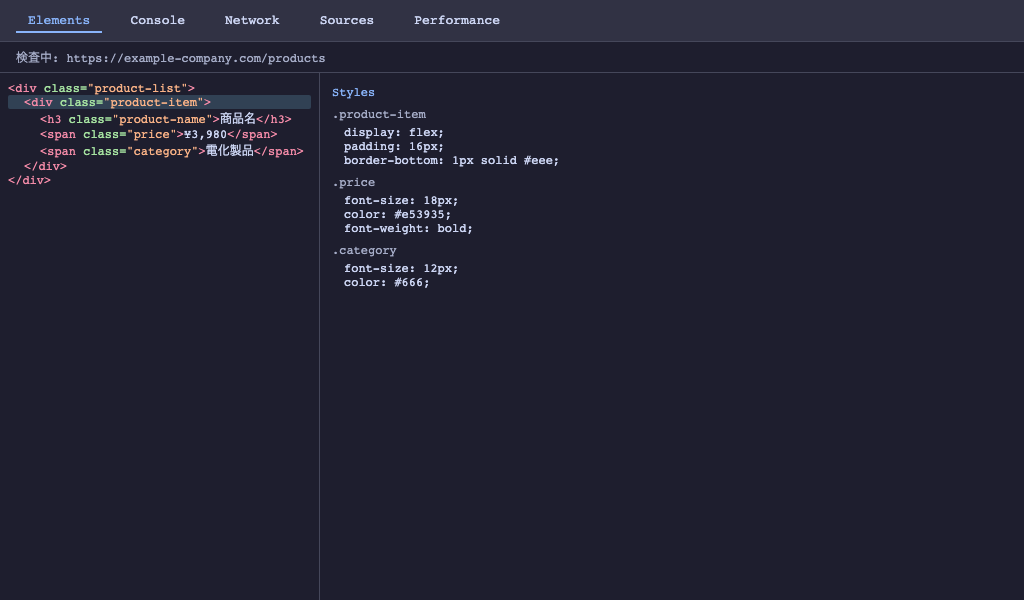
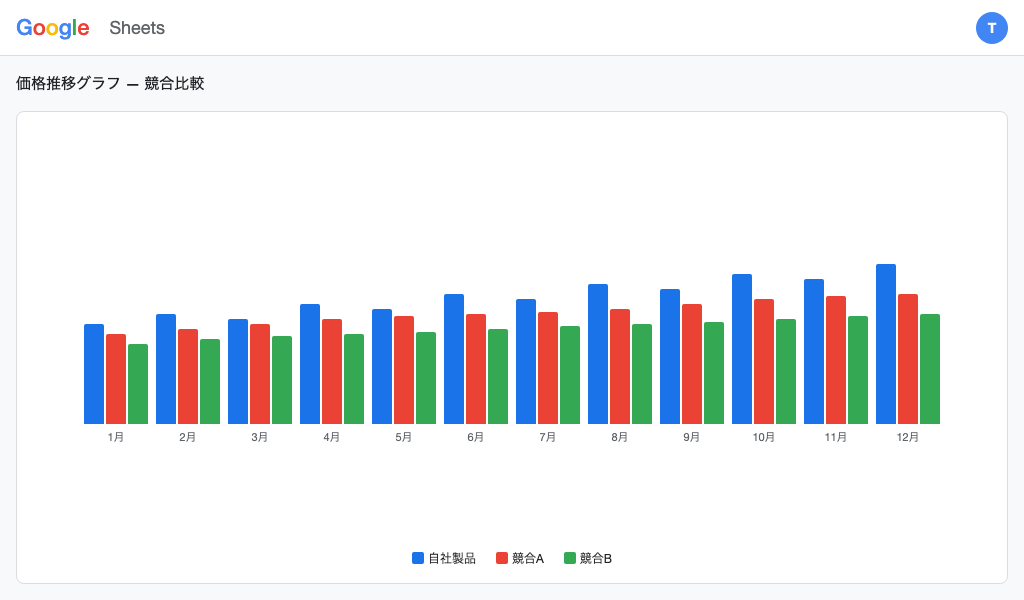
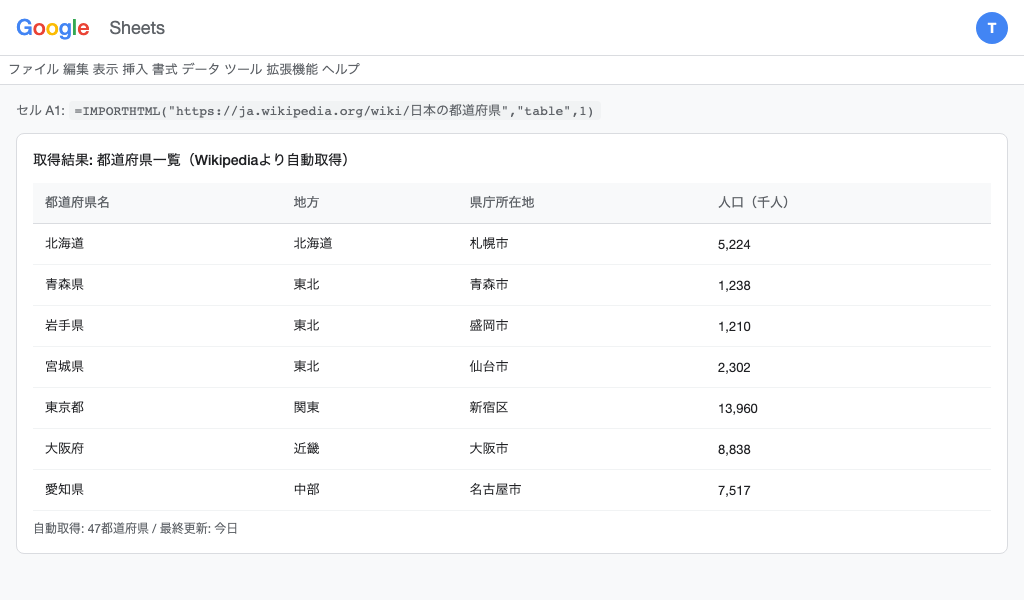
スクレイピングでデータを正確に抽出するには、HTMLの構造を理解することが必要です。
HTML
<div class="company-card">
<h3 class="name">株式会社ABC</h3>
<p class="address">東京都渋谷区...</p>
<span class="tel">03-1234-5678</span>
</div>
ブラウザの「開発者ツール」(F12キー)でHTMLの構造をリアルタイムに確認できます。
基本用語
| 用語 | 説明 | 例 |
|---|---|---|
| タグ | HTMLの要素を囲む記号 | <h3>, <div> |
| クラス | 要素のカテゴリ名 | class="name" |
| ID | 要素の一意な識別子 | id="main" |
| DOM | HTMLのツリー構造 | 親→子の階層 |
| 属性 | タグに付加する情報 | href="..." |